
Spring IOC
IOC
IoC (Inversion of Control )即控制反转/反转控制。它是一种思想不是一个技术实现。描述的是:Java 开发领域对象的创建以及管理的问题。
IoC 的思想就是两方之间不互相依赖,由第三方容器来管理相关资源。这样有什么好处呢?
对象之间的耦合度或者说依赖程度降低;
资源变的容易管理;比如你用 Spring 容器提供的话很容易就可以实现一个单例。
@Autowired 和 @Resource 的区别
@Autowired是 Spring 提供的注解,@Resource是 JDK 提供的注解。Autowired默认的注入方式为byType(根据类型进行匹配),@Resource默认注入方式为byName(根据名称进行匹配)。当一个接口存在多个实现类的情况下,
@Autowired和@Resource都需要通过名称才能正确匹配到对应的 Bean。Autowired可以通过@Qualifier注解来显式指定名称,@Resource可以通过name属性来显式指定名称。@Autowired支持在构造函数、方法、字段和参数上使用。@Resource主要用于字段和方法上的注入,不支持在构造函数或参数上使用。
考虑到 @Resource 的语义更清晰(名称优先),并且是 Java 标准,能减少对 Spring 框架的强耦合,我们通常更推荐使用 @Resource,尤其是在需要按名称注入的场景下。而 @Autowired 配合构造器注入,在实现依赖注入的不可变性和强制性方面有优势,也是一种非常好的实践。
注入 Bean 的方式有哪些?
依赖注入 (Dependency Injection, DI) 的常见方式:
构造函数注入:通过类的构造函数来注入依赖项。
Setter 注入:通过类的 Setter 方法来注入依赖项。
Field(字段) 注入:直接在类的字段上使用注解(如
@Autowired或@Resource)来注入依赖项。
构造函数注入示例:
@Service
public class UserService {
private final UserRepository userRepository;
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
}Setter 注入示例:
@Service
public class UserService {
private UserRepository userRepository;
// 在 Spring 4.3 及以后的版本,特定情况下 @Autowired 可以省略不写
@Autowired
public void setUserRepository(UserRepository userRepository) {
this.userRepository = userRepository;
}
}Field 注入示例:
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
}Bean的作用域
Spring 中 Bean 的作用域通常有下面几种:
singleton : IoC 容器中只有唯一的 bean 实例。Spring 中的 bean 默认都是单例的,是对单例设计模式的应用。
prototype : 每次获取都会创建一个新的 bean 实例。也就是说,连续
getBean()两次,得到的是不同的 Bean 实例。request (仅 Web 应用可用): 每一次 HTTP 请求都会产生一个新的 bean(请求 bean),该 bean 仅在当前 HTTP request 内有效。
session (仅 Web 应用可用) : 每一次来自新 session 的 HTTP 请求都会产生一个新的 bean(会话 bean),该 bean 仅在当前 HTTP session 内有效。
application/global-session (仅 Web 应用可用):每个 Web 应用在启动时创建一个 Bean(应用 Bean),该 bean 仅在当前应用启动时间内有效。
websocket (仅 Web 应用可用):每一次 WebSocket 会话产生一个新的 bean。
配置方式 @Scope:
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public Person personPrototype() {
return new Person();
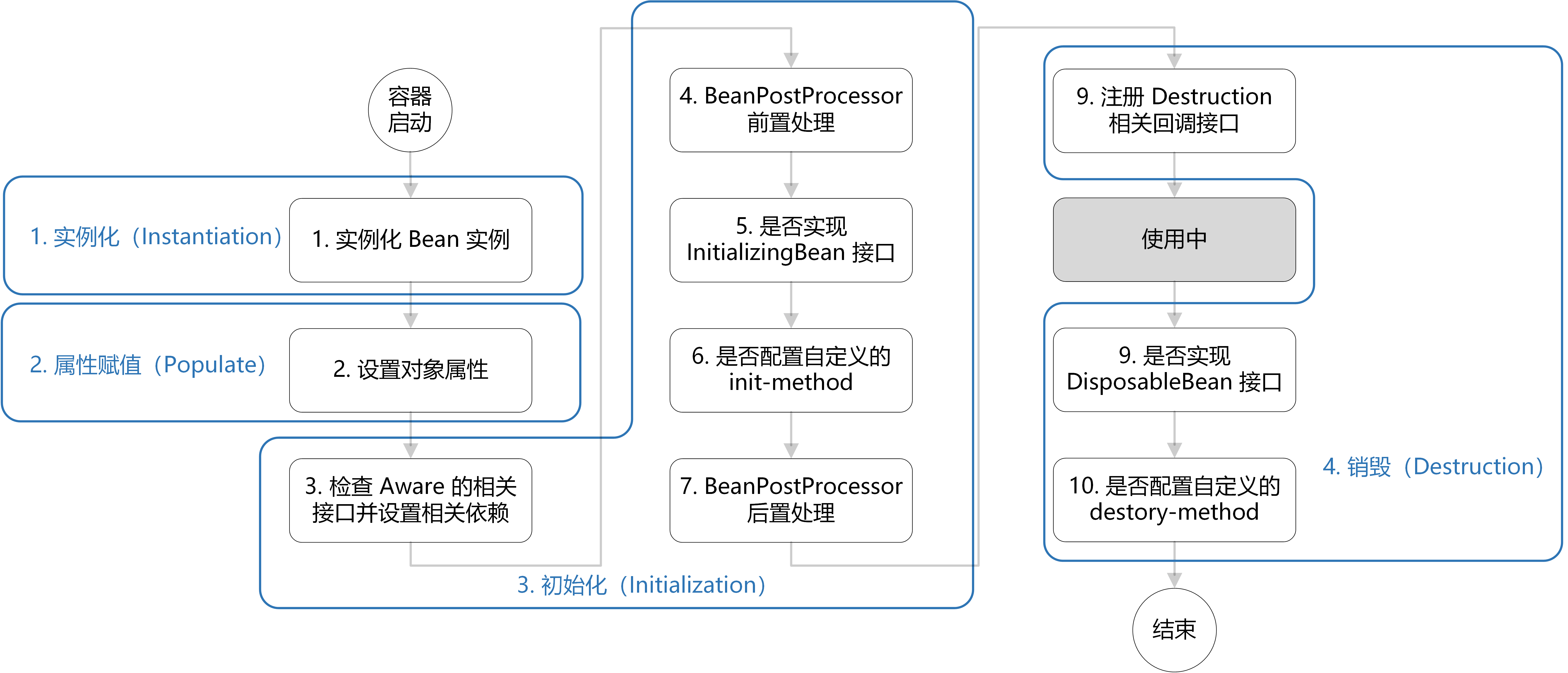
}Bean的生命周期
创建 Bean 的实例:Bean 容器首先会找到配置文件中的 Bean 定义,然后使用 Java 反射 API 来创建 Bean 的实例。
Bean 属性赋值/填充:为 Bean 设置相关属性和依赖,例如
@Autowired等注解注入的对象、@Value注入的值、setter方法或构造函数注入依赖和值、@Resource注入的各种资源。Bean 初始化:
如果 Bean 实现了
BeanNameAware接口,调用setBeanName()方法,传入 Bean 的名字。如果 Bean 实现了
BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。如果 Bean 实现了
BeanFactoryAware接口,调用setBeanFactory()方法,传入BeanFactory对象的实例。与上面的类似,如果实现了其他
*.Aware接口,就调用相应的方法。如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessBeforeInitialization()方法如果 Bean 实现了
InitializingBean接口,执行afterPropertiesSet()方法。如果 Bean 在配置文件中的定义包含
init-method属性,执行指定的方法。如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessAfterInitialization()方法。
销毁 Bean:销毁并不是说要立马把 Bean 给销毁掉,而是把 Bean 的销毁方法先记录下来,将来需要销毁 Bean 或者销毁容器的时候,就调用这些方法去释放 Bean 所持有的资源。
如果 Bean 实现了
DisposableBean接口,执行destroy()方法。如果 Bean 在配置文件中的定义包含
destroy-method属性,执行指定的 Bean 销毁方法。或者,也可以直接通过@PreDestroy注解标记 Bean 销毁之前执行的方法。
记忆:
整体上可以简单分为四步:实例化 —> 属性赋值 —> 初始化 —> 销毁。
初始化这一步涉及到的步骤比较多,包含
Aware接口的依赖注入、BeanPostProcessor在初始化前后的处理以及InitializingBean和init-method的初始化操作。销毁这一步会注册相关销毁回调接口,最后通过
DisposableBean和destory-method进行销毁。
Spring AOP
AOP
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
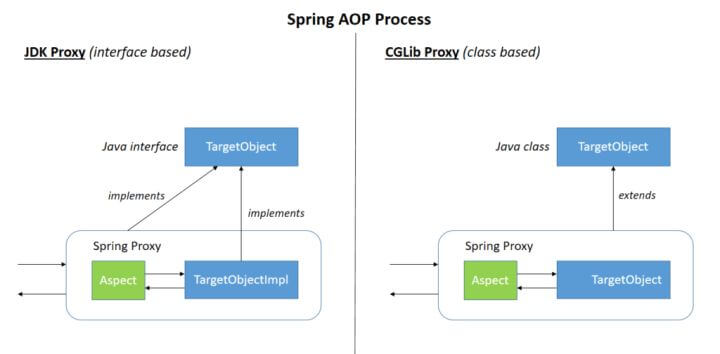
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理
与AspectJ AOP的区别
AOP常见的通知类型
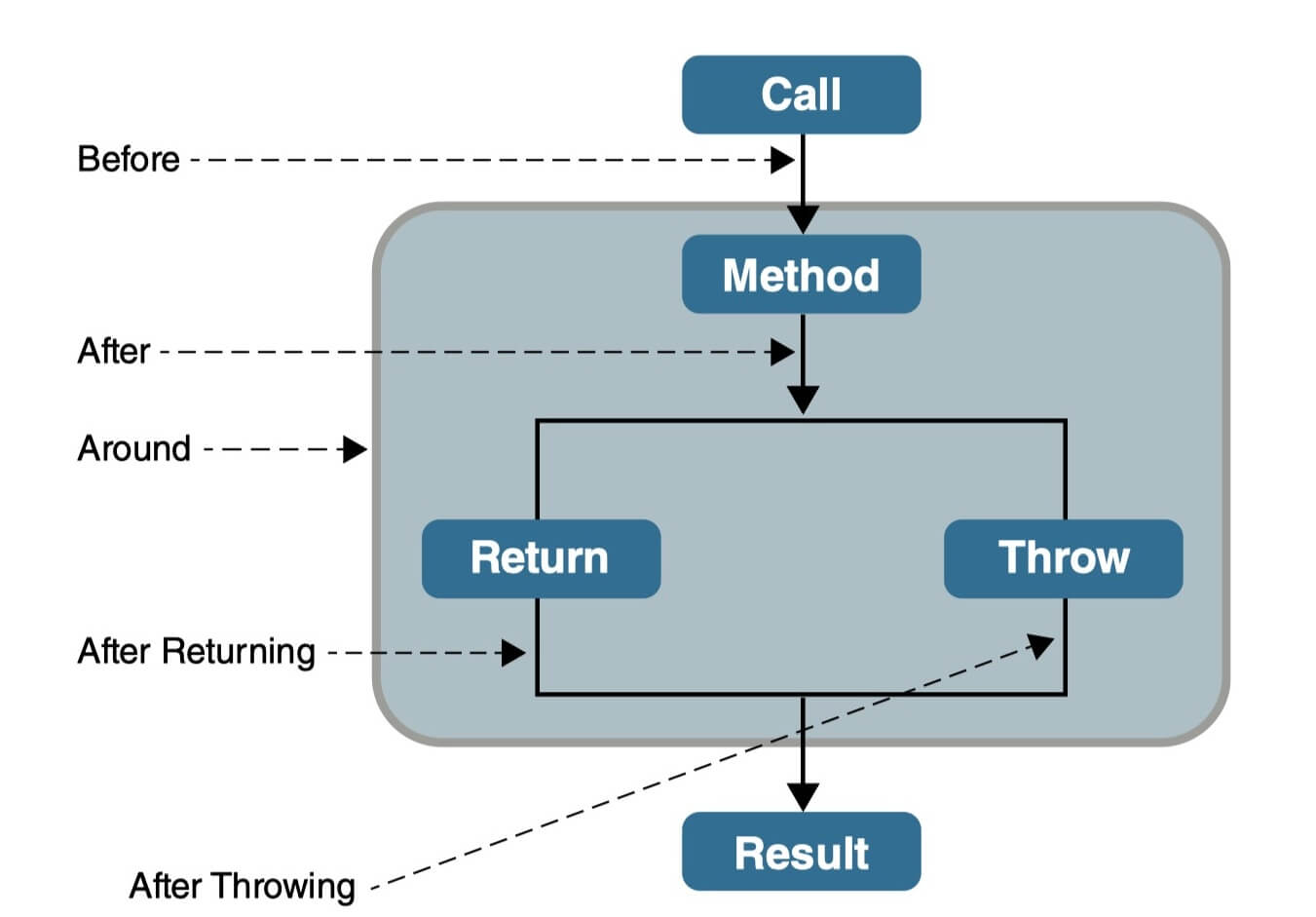
Before(前置通知):目标对象的方法调用之前触发
After (后置通知):目标对象的方法调用之后触发
AfterReturning(返回通知):目标对象的方法调用完成,在返回结果值之后触发
AfterThrowing(异常通知):目标对象的方法运行中抛出 / 触发异常后触发。AfterReturning 和 AfterThrowing 两者互斥。如果方法调用成功无异常,则会有返回值;如果方法抛出了异常,则不会有返回值。
Around (环绕通知):编程式控制目标对象的方法调用。环绕通知是所有通知类型中可操作范围最大的一种,因为它可以直接拿到目标对象,以及要执行的方法,所以环绕通知可以任意的在目标对象的方法调用前后搞事,甚至不调用目标对象的方法
Spring MVC
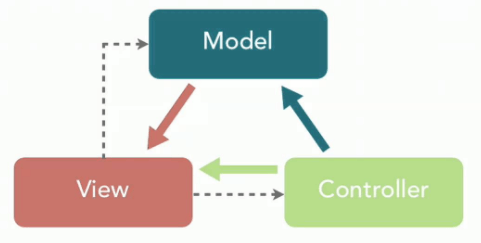
MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。
核心组件
DispatcherServlet:核心的中央处理器,负责接收请求、分发,并给予客户端响应。HandlerMapping:处理器映射器,根据 URL 去匹配查找能处理的Handler,并会将请求涉及到的拦截器和Handler一起封装。HandlerAdapter:处理器适配器,根据HandlerMapping找到的Handler,适配执行对应的Handler;Handler:请求处理器,处理实际请求的处理器。ViewResolver:视图解析器,根据Handler返回的逻辑视图 / 视图,解析并渲染真正的视图,并传递给DispatcherServlet响应客户端
工作原理
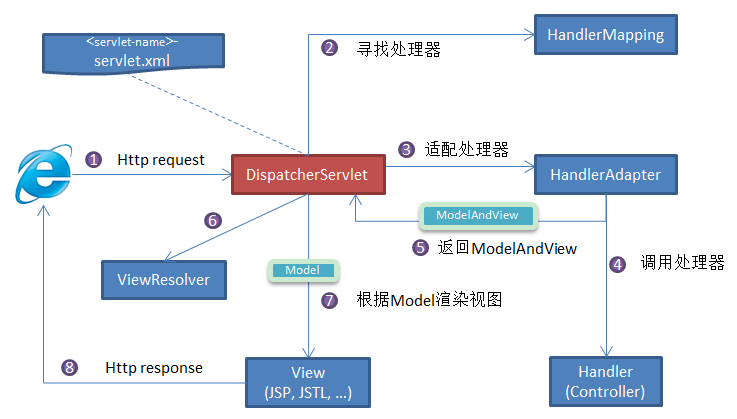
流程说明(重要):
客户端(浏览器)发送请求,
DispatcherServlet拦截请求。DispatcherServlet根据请求信息调用HandlerMapping。HandlerMapping根据 URL 去匹配查找能处理的Handler(也就是我们平常说的Controller控制器) ,并会将请求涉及到的拦截器和Handler一起封装。DispatcherServlet调用HandlerAdapter适配器执行Handler。Handler完成对用户请求的处理后,会返回一个ModelAndView对象给DispatcherServlet,ModelAndView顾名思义,包含了数据模型以及相应的视图的信息。Model是返回的数据对象,View是个逻辑上的View。ViewResolver会根据逻辑View查找实际的View。DispaterServlet把返回的Model传给View(视图渲染)。把
View返回给请求者(浏览器)
上述流程是传统开发模式(JSP,Thymeleaf 等)的工作原理。然而现在主流的开发方式是前后端分离,这种情况下 Spring MVC 的 View 概念发生了一些变化。由于 View 通常由前端框架(Vue, React 等)来处理,后端不再负责渲染页面,而是只负责提供数据,因此:
前后端分离时,后端通常不再返回具体的视图,而是返回纯数据(通常是 JSON 格式),由前端负责渲染和展示。
View的部分在前后端分离的场景下往往不需要设置,Spring MVC 的控制器方法只需要返回数据,不再返回ModelAndView,而是直接返回数据,Spring 会自动将其转换为 JSON 格式。相应的,ViewResolver也将不再被使用。
怎么做到呢?
使用
@RestController注解代替传统的@Controller注解,这样所有方法默认会返回 JSON 格式的数据,而不是试图解析视图。如果你使用的是
@Controller,可以结合@ResponseBody注解来返回 JSON。
Spring 使用的设计模式
工厂设计模式 : Spring 使用工厂模式通过
BeanFactory、ApplicationContext创建 bean 对象。代理设计模式 : Spring AOP 功能的实现。
单例设计模式 : Spring 中的 Bean 默认都是单例的。
模板方法模式 : Spring 中
jdbcTemplate、hibernateTemplate等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
适配器模式 : Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配
Controller。
Spring 循环依赖
循环依赖是指 Bean 对象循环引用,是两个或多个 Bean 之间相互持有对方的引用,例如 A → B → A。
Spring 框架通过使用三级缓存来解决这个问题,确保即使在循环依赖的情况下也能正确创建 Bean。
Spring 中的三级缓存其实就是三个 Map,如下:
// 一级缓存
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
// 三级缓存
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);简单来说,Spring 的三级缓存包括:
一级缓存(singletonObjects):存放最终形态的 Bean(已经实例化、属性填充、初始化),单例池,为“Spring 的单例属性”⽽⽣。一般情况我们获取 Bean 都是从这里获取的,但是并不是所有的 Bean 都在单例池里面,例如原型 Bean 就不在里面。
二级缓存(earlySingletonObjects):存放过渡 Bean(半成品,尚未属性填充),也就是三级缓存中
ObjectFactory产生的对象,与三级缓存配合使用的,可以防止 AOP 的情况下,每次调用ObjectFactory#getObject()都是会产生新的代理对象的。三级缓存(singletonFactories):存放
ObjectFactory,ObjectFactory的getObject()方法(最终调用的是getEarlyBeanReference()方法)可以生成原始 Bean 对象或者代理对象(如果 Bean 被 AOP 切面代理)。三级缓存只会对单例 Bean 生效。
接下来说一下 Spring 创建 Bean 的流程:
先去 一级缓存
singletonObjects中获取,存在就返回;如果不存在或者对象正在创建中,于是去 二级缓存
earlySingletonObjects中获取;如果还没有获取到,就去 三级缓存
singletonFactories中获取,通过执行ObjectFacotry的getObject()就可以获取该对象,获取成功之后,从三级缓存移除,并将该对象加入到二级缓存中。
在三级缓存中存储的是 ObjectFacoty :
public interface ObjectFactory<T> {
T getObject() throws BeansException;
}Spring 在创建 Bean 的时候,如果允许循环依赖的话,Spring 就会将刚刚实例化完成,但是属性还没有初始化完的 Bean 对象给提前暴露出去,这里通过 addSingletonFactory 方法,向三级缓存中添加一个 ObjectFactory 对象:
// AbstractAutowireCapableBeanFactory # doCreateBean #
public abstract class AbstractAutowireCapableBeanFactory ... {
protected Object doCreateBean(...) {
//...
// 支撑循环依赖:将 ()->getEarlyBeanReference 作为一个 ObjectFactory 对象的 getObject() 方法加入到三级缓存中
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
}那么上边在说 Spring 创建 Bean 的流程时说了,如果一级缓存、二级缓存都取不到对象时,会去三级缓存中通过 ObjectFactory 的 getObject 方法获取对象。
Spring 事务
事务管理方式
编程式事务管理
通过 TransactionTemplate或者TransactionManager手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。
使用TransactionTemplate 进行编程式事务管理的示例代码如下:
@Autowired
private TransactionTemplate transactionTemplate;
public void testTransaction() {
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
@Override
protected void doInTransactionWithoutResult(TransactionStatus transactionStatus) {
try {
// .... 业务代码
} catch (Exception e){
//回滚
transactionStatus.setRollbackOnly();
}
}
});
}使用 TransactionManager 进行编程式事务管理的示例代码如下:
@Autowired
private PlatformTransactionManager transactionManager;
public void testTransaction() {
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
// .... 业务代码
transactionManager.commit(status);
} catch (Exception e) {
transactionManager.rollback(status);
}
}声明式事务管理
推荐使用(代码侵入性最小),实际是通过 AOP 实现(基于@Transactional 的全注解方式使用最多)。
使用 @Transactional注解进行事务管理的示例代码如下:
@Transactional(propagation = Propagation.REQUIRED)
public void aMethod {
//do something
B b = new B();
C c = new C();
b.bMethod();
c.cMethod();
}事务属性
事务传播行为
事务传播行为是为了解决业务层方法之间互相调用的事务问题。
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。
举个例子:我们在 A 类的aMethod()方法中调用了 B 类的 bMethod() 方法。这个时候就涉及到业务层方法之间互相调用的事务问题。如果我们的 bMethod()如果发生异常需要回滚,如何配置事务传播行为才能让 aMethod()也跟着回滚呢?
1.PROPAGATION_REQUIRED
使用的最多的一个事务传播行为,@Transactional注解默认使用就是这个事务传播行为。如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。也就是说:
如果外部方法没有开启事务的话,Propagation.REQUIRED修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
如果外部方法开启事务并且被Propagation.REQUIRED的话,所有Propagation.REQUIRED修饰的内部方法和外部方法均属于同一事务 ,只要一个方法回滚,整个事务均回滚。
2.PROPAGATION_REQUIRES_NEW
创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,Propagation.REQUIRES_NEW修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
举个例子:如果我们上面的bMethod()使用PROPAGATION_REQUIRES_NEW事务传播行为修饰,aMethod还是用PROPAGATION_REQUIRED修饰的话。如果aMethod()发生异常回滚,bMethod()不会跟着回滚,因为 bMethod()开启了独立的事务。但是,如果 bMethod()抛出了未被捕获的异常并且这个异常满足事务回滚规则的话,aMethod()同样也会回滚,因为这个异常被 aMethod()的事务管理机制检测到了。
3.TransactionDefinition.PROPAGATION_NESTED
如果当前存在事务,则创建一个事务作为当前事务的嵌套事务执行; 如果当前没有事务,就执行TransactionDefinition.PROPAGATION_REQUIRED类似的操作。也就是说:
在外部方法开启事务的情况下,在内部开启一个新的事务,作为嵌套事务存在。
如果外部方法无事务,则单独开启一个事务,与 PROPAGATION_REQUIRED 类似。
TransactionDefinition.PROPAGATION_NESTED代表的嵌套事务以父子关系呈现,其核心理念是子事务不会独立提交,依赖于父事务,在父事务中运行;当父事务提交时,子事务也会随着提交,理所当然的,当父事务回滚时,子事务也会回滚;
与TransactionDefinition.PROPAGATION_REQUIRES_NEW区别于:PROPAGATION_REQUIRES_NEW是独立事务,不依赖于外部事务,以平级关系呈现,执行完就会立即提交,与外部事务无关;
子事务也有自己的特性,可以独立进行回滚,不会引发父事务的回滚,但是前提是需要处理子事务的异常,避免异常被父事务感知导致外部事务回滚;
事务超时属性
所谓事务超时,就是指一个事务所允许执行的最长时间,如果超过该时间限制但事务还没有完成,则自动回滚事务。
在TransactionDefinition 中以 int 的值来表示超时时间,其单位是秒,默认值为-1,这表示事务的超时时间取决于底层事务系统或者没有超时时间。
事务只读属性
对于只有读取数据查询的事务,可以指定事务类型为 readonly,即只读事务。只读事务不涉及数据的修改,数据库会提供一些优化手段,适合用在有多条数据库查询操作的方法中。
只读开启事务的判断依据:
如果一次执行单条查询语句,则没有必要启用事务支持,数据库默认支持 SQL 执行期间的读一致性;
如果一次执行多条查询语句,例如统计查询,报表查询,在这种场景下,多条查询 SQL 必须保证整体的读一致性,否则,在前条 SQL 查询之后,后条 SQL 查询之前,数据被其他用户改变,则该次整体的统计查询将会出现读数据不一致的状态,此时,应该启用事务支持。
事务回滚规则
默认情况下,事务只有遇到运行期异常(RuntimeException 的子类)时才会回滚,Error 也会导致事务回滚。但是,在遇到检查型(Checked)异常时不会回滚。
设置rollbackFor可以指定回滚异常类型:
@Transactional(rollbackFor = Exception.class)@Transactional 注解原理
@Transactional 的工作机制是基于 AOP 实现的,AOP 又是使用动态代理实现的。如果目标对象实现了接口,默认情况下会采用 JDK 的动态代理,如果目标对象没有实现了接口,会使用 CGLIB 动态代理。
如果一个类或者一个类中的 public 方法上被标注@Transactional 注解的话,Spring 容器就会在启动的时候为其创建一个代理类,在调用被@Transactional 注解的 public 方法的时候,实际调用的是,TransactionInterceptor 类中的 invoke()方法。这个方法的作用就是在目标方法之前开启事务,方法执行过程中如果遇到异常的时候回滚事务,方法调用完成之后提交事务。
Spring Boot
过滤器、拦截器、监听器
过滤器(Filter):当有一堆请求,只希望符合预期的请求进来。
拦截器(Interceptor):想要干涉预期的请求。
监听器(Listener):想要监听这些请求具体做了什么。
过滤器是在请求进入容器后,但还没有进入 Servlet 之前进行预处理的。
拦截器是在请求进入控制器(Controller) 之前进行预处理的。
过滤器依赖于 Servlet 容器。而拦截器依赖于 Spring 的 IoC 容器,因此可以通过注入的方式获取容器当中的对象。
监听器用于监听 Web 应用中某些对象的创建、销毁、增加、修改、删除等动作,然后做出相应的处理。
过滤器
过滤敏感词汇(防止sql注入)
设置字符编码
URL级别的权限访问控制
压缩响应信息
过滤器的创建和销毁都由 Web 服务器负责,Web 应用程序启动的时候,创建过滤器对象,为后续的请求过滤做好准备。
过滤器可以有很多个,一个个过滤器组合起来就成了 FilterChain,也就是过滤器链。
在 Spring 中,过滤器都默认继承了 OncePerRequestFilter。OncePerRequestFilter 的作用就是确保一次请求只通过一次过滤器,而不重复执行。
拦截器
登录验证,判断用户是否登录
权限验证,判断用户是否有权限访问资源,如校验token
日志记录,记录请求操作日志(用户ip,访问时间等),以便统计请求访问量
处理cookie、本地化、国际化、主题等
性能监控,监控请求处理时长等
自动装配原理
SpringBoot 定义了一套接口规范,这套规范规定:SpringBoot 在启动时会扫描外部引用 jar 包中的META-INF/spring.factories文件,将文件中配置的类型信息加载到 Spring 容器(此处涉及到 JVM 类加载机制与 Spring 的容器知识),并执行类中定义的各种操作。
对于外部 jar 来说,只需要按照 SpringBoot 定义的标准,就能将自己的功能装置进 SpringBoot。
自 Spring Boot 3.0 开始,自动配置包的路径从META-INF/spring.factories 修改为 METAINF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports。
1.核心入口:@SpringBootApplication
启动类@SpringBootApplication 注解是一个复合注解,其中最重要的是:@EnableAutoConfiguration,开启自动配置功能。
而在 @EnableAutoConfiguration 内部,又引入了:@Import(AutoConfigurationImportSelector.class),加载自动装配类。
2.AutoConfigurationImportSelector
AutoConfigurationImportSelector 类会去扫描类路径下所有 Jar 包中的.imports或.factories文件,读取备选自动配置类。
3.读取.imports或.factories文件
这些文件里列出了大量备选的自动配置类(全限定类名),比如 JdbcTemplateAutoConfiguration、RedisAutoConfiguration 等。
4.根据条件注解@ConditionalOnXXX筛选需要加载的配置
Spring Boot 提供的部分条件注解:
@ConditionalOnBean:当容器里有指定 Bean 的条件下@ConditionalOnMissingBean:当容器里没有指定 Bean 的情况下@ConditionalOnSingleCandidate:当指定 Bean 在容器中只有一个,或者虽然有多个但是指定首选 Bean@ConditionalOnClass:当类路径下有指定类的条件下@ConditionalOnMissingClass:当类路径下没有指定类的条件下@ConditionalOnProperty:指定的属性是否有指定的值@ConditionalOnResource:类路径是否有指定的值
总结
Spring Boot 通过@EnableAutoConfiguration开启自动装配,通过 SpringFactoriesLoader 最终加载META-INF/spring.factories中的自动配置类实现自动装配,自动配置类其实就是通过@Conditional按需加载的配置类,想要其生效必须引入spring-boot-starter-xxx包实现起步依赖

